
1. Introducción
Core-Admin incluye, dentro del módulo MySQL Manager, una herramienta de diagnóstico que permite capturar en vivo todas las consultas SQL que un servidor MySQL/MariaDB está ejecutando durante un breve periodo de tiempo y presentar un informe resumido que ayuda a localizar problemas de rendimiento.
A diferencia de mirar procesos puntuales (SHOW PROCESSLIST), esta opción registra todas las sentencias que pasan por el servidor durante la ventana de captura y, a partir de ellas, calcula:
- La tasa media de consultas por segundo que está soportando el servidor.
- El Top de consultas más repetidas, agrupando las que tienen la misma forma (independientemente de los valores concretos), de modo que se ven enseguida los grupos de consultas que se ejecutan en exceso.
- El listado completo de las sentencias capturadas, para análisis detallado.
El objetivo es responder con un par de clics a preguntas como: ¿este servidor recibe demasiadas consultas?, ¿qué aplicación o qué consulta concreta está generando la mayor parte de la carga?, ¿hay una misma consulta repitiéndose cientos de veces (problema N+1, falta de caché, índice ausente)?
Internamente, la herramienta activa de forma temporal el general_log de MySQL/MariaDB, lo vuelca a un fichero, espera el periodo indicado, lo desactiva y procesa el resultado. Todo el ciclo es automático: el general_log queda desactivado al terminar.
Este artículo explica dónde está la opción, cómo se usa, qué contiene el informe y cómo interpretarlo para localizar puntos de mejora.
2. Requisitos previos
- Core-Admin instalado con el módulo MySQL Manager activo en el servidor a inspeccionar.
- Acceso al panel web de Core-Admin con permisos de administrador (la opción requiere privilegios de administrador del servidor).
- Uno o varios servidores MySQL/MariaDB gestionados por Core-Admin en ese host.
3. Dónde se encuentra la opción
La función está en la barra de herramientas del módulo MySQL Manager, bajo la sección Report.
Para llegar a ella:
- Accede al panel web de Core-Admin.
- Entra en el módulo MySQL Manager del servidor que quieras analizar.
- En la barra de herramientas lateral, dentro de la sección Report, pulsa el botón Inspect SQL sentences.
Arrancamos:
Luego:
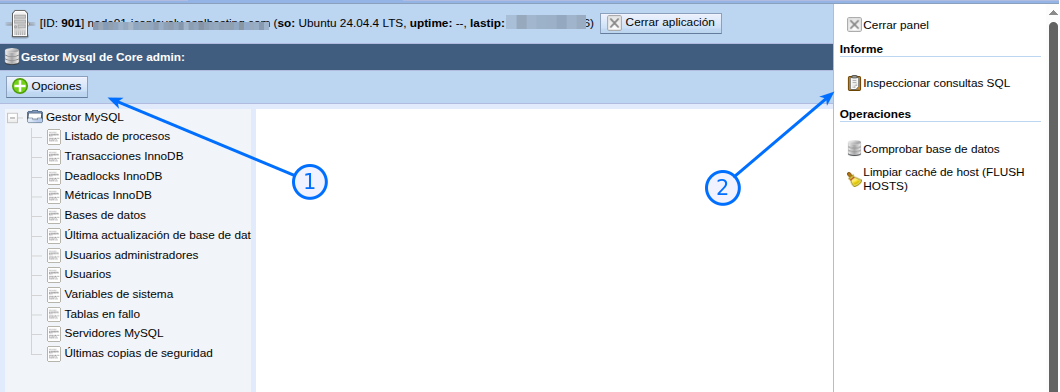
4. Cuadro de diálogo: opciones disponibles
Al pulsar el botón se abre un diálogo de confirmación con dos campos:
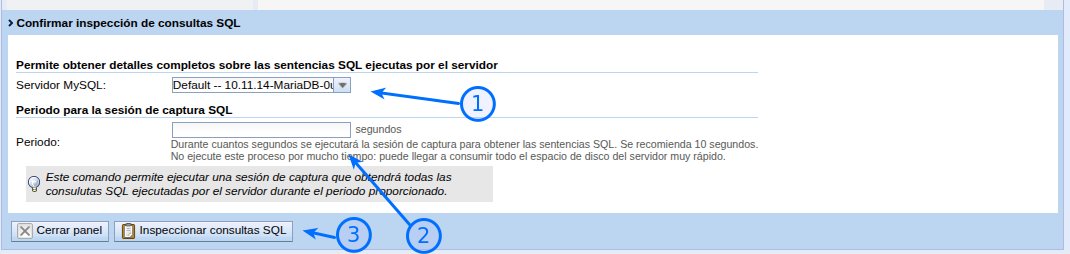
4.1. Servidor MySQL/MariaDB a inspeccionar
En el desplegable mysql_server aparece la lista de servidores MySQL/MariaDB que Core-Admin tiene configurados en ese host. Selecciona aquel cuya actividad SQL quieras capturar. Si solo hay un servidor, aparecerá seleccionado por defecto.
4.2. Periodo de captura (en segundos)
El campo period indica cuántos segundos se mantiene activa la captura de sentencias SQL. El valor recomendado y por defecto es 10 segundos.
Importante — no prolongues la captura más de lo necesario. Mientras la captura está activa, MySQL/MariaDB escribe en disco todas las consultas que recibe. En un servidor con mucha actividad, una ventana larga puede generar un fichero de log enorme y llenar el disco muy rápidamente. Para un diagnóstico normal, 10–15 segundos durante un momento de carga representativa son más que suficientes. Si necesitas observar un pico puntual, lanza la captura justo cuando se produzca.
Tras confirmar, el panel quedará a la espera durante el número de segundos indicado (la captura es síncrona) y a continuación mostrará el informe como texto plano.
5. Cómo funciona internamente
Entender el mecanismo ayuda a interpretar los resultados y a usar la herramienta con seguridad:
- Se obtiene una conexión administrativa al servidor seleccionado.
- Se genera un fichero temporal de log (en
/var/log, o en/tmpen Ubuntu Focal/Jammy/Noble por las restricciones de AppArmor sobremysqld) y se le asignan permisos al usuariomysql. - Se ejecuta
SET GLOBAL general_log_file='...'ySET GLOBAL general_log=1para empezar a registrar toda la actividad. - Se espera el número de segundos indicado en period.
- Se ejecuta
SET GLOBAL general_log=0para desactivar el registro. - Se procesa el fichero generado, se normalizan y agrupan las consultas y se construye el informe.
Conviene tener presente que el general_log es global al servidor: la captura recoge la actividad de todas las bases de datos y todas las aplicaciones que usan ese MySQL/MariaDB, no de una sola. Esto es justo lo que interesa para un diagnóstico global de carga, pero hay que tenerlo en cuenta al atribuir consultas a una aplicación concreta.
6. Contenido del informe
El informe se presenta en el panel como texto plano y se compone de tres bloques.
6.1. Estadísticas generales
Una pequeña tabla resumen con las métricas globales de la captura:
| Métrica | Significado |
|---|---|
| Detected queries | Número total de sentencias detectadas durante la ventana de captura. |
| Lines processed | Líneas del log procesadas (incluye continuaciones de consultas multilínea). |
| Capture period | Duración real de la captura, en segundos. |
| AVG SQL/seconds | Media de consultas por segundo (Detected queries ÷ Capture period). Es la métrica clave para valorar si el servidor está sobrecargado de consultas. |
6.2. Top de consultas (Top SQL query)
Una tabla con las 10 consultas más repetidas durante la captura, ordenadas de mayor a menor frecuencia. Cada fila contiene:
| Columna | Significado |
|---|---|
| id | Posición en el ranking (1 = la más repetida). |
| Count | Número de veces que se ejecutó esa forma de consulta en la ventana. |
| Top SQL query | La consulta normalizada. |
El detalle importante es la normalización: antes de contar, la herramienta sustituye los valores literales por marcadores genéricos, de forma que dos consultas idénticas en estructura pero con distintos valores se cuentan como la misma. Por ejemplo:
SELECT * FROM productos WHERE id = 8457 LIMIT 1
SELECT * FROM productos WHERE id = 9921 LIMIT 1
se normalizan ambas a:
SELECT * FROM productos WHERE id = num LIMIT num
Los reemplazos que aplica son:
- Números →
num - Cadenas entre comillas simples →
'xxx' - Cadenas entre comillas dobles →
"xxx"
Gracias a esto, el Top agrupa grupos de consultas con la misma forma, que es exactamente lo que permite detectar patrones de uso abusivo (la misma consulta lanzada cientos de veces con distintos parámetros).
6.3. Listado completo de consultas
La tercera tabla contiene todas las sentencias capturadas, en orden cronológico, con las columnas:
| Columna | Significado |
|---|---|
| id | Número de orden de la sentencia dentro de la captura. |
| Type | Tipo de evento: Query (consulta SQL) o Connect (apertura de conexión). |
| Ellapsed | Valor relativo entre entradas consecutivas; sirve como indicador de secuencia, no como tiempo exacto de ejecución de la consulta. |
| SQL Query | La sentencia tal cual se ejecutó (sin normalizar, con sus valores reales). |
Este bloque es el material de análisis fino: una vez que el Top te ha señalado qué forma de consulta abusa, aquí puedes ver las instancias reales con sus valores concretos, las conexiones que se abren y la secuencia en la que todo ocurre.
7. Cómo usar los datos para localizar puntos de mejora
El informe está pensado para ir de lo general a lo concreto. Una metodología práctica:
7.1. Paso 1 — valorar la carga global con AVG SQL/seconds
Es el primer indicador. No hay un umbral universal (depende del hardware y de la aplicación), pero como orientación:
- Decenas de consultas/seg: actividad normal en la mayoría de hostings.
- Cientos de consultas/seg de forma sostenida: empieza a ser carga alta; conviene revisar el Top.
- Miles de consultas/seg: salvo en servidores muy dimensionados, suele indicar un problema (bucle de consultas, falta de caché, escaneo de tablas, ataque o bot).
Como la captura es corta, repítela un par de veces en momentos distintos para distinguir un pico puntual de una carga sostenida.
7.2. Paso 2 — identificar los grupos abusivos con el Top
El Top de consultas es donde normalmente está el problema. Busca patrones:
-
Una consulta con un
Countdesproporcionado respecto al resto: es la principal candidata a optimizar. Si una sola forma de consulta representa una fracción enorme del total, ahí está el cuello de botella. -
Misma consulta
SELECTrepetida cientos de veces con distintosid: patrón clásico de problema N+1 (la aplicación hace una consulta por cada elemento de una lista en lugar de una sola consulta conjunta) o de ausencia de caché (se relanza la misma consulta que debería estar cacheada). - Consultas de catálogo/configuración repetidas constantemente (típicas de PrestaShop, Joomla, WordPress, VirtueMart…): suelen indicar que falta una capa de caché de objeto (Redis/Memcached) o que un módulo está mal configurado.
-
Connectmuy frecuentes: si ves muchas aperturas de conexión, la aplicación no está reutilizando conexiones (falta de connection pooling o conexiones persistentes), lo que añade sobrecarga.
7.3. Paso 3 — bajar al detalle con el listado completo
Con la forma de consulta ya localizada en el Top, usa el listado completo para:
- Ver los valores reales de los parámetros (qué tabla, qué
id, qué filtros), lo que ayuda a localizar la base de datos y la aplicación responsable. - Confirmar la secuencia: si las instancias aparecen agrupadas y consecutivas, refuerza la hipótesis de un bucle N+1.
- Detectar consultas sin índice evidente (
WHEREsobre columnas no indexadas,LIKE '%...%', ausencia deLIMITen listados grandes) como candidatas a optimización de esquema.
7.4. Paso 4 — actuar
Según lo encontrado, las acciones habituales son:
-
Añadir o revisar índices en las columnas usadas en los
WHERE/JOINde las consultas más repetidas o más lentas. - Activar caché (de objeto, de página o de consulta) en la aplicación para eliminar consultas repetitivas.
- Corregir patrones N+1 en el código de la aplicación (cargar en una sola consulta lo que se está pidiendo en bucle).
- Revisar configuración de la aplicación o de módulos que generen consultas innecesarias.
- Si el origen es tráfico anómalo (bots, ataques), abordarlo desde la capa web (límites de tasa, bloqueos) en lugar de en la base de datos.
Sugerencia: para confirmar que una consulta concreta puede mejorar con un índice, puedes complementar este informe con un
EXPLAINde la sentencia (disponible también desde MySQL Manager) y revisar si está haciendo un escaneo completo de tabla.
8. Buenas prácticas y advertencias
-
Mantén el periodo corto (10–15 s). El
general_logescribe cada consulta en disco; periodos largos en servidores activos pueden llenar el disco rápidamente. - Captura en momentos representativos. Para diagnosticar un problema, lanza la captura cuando el síntoma se esté produciendo (lentitud, picos de carga).
- Repite la captura varias veces para distinguir picos puntuales de carga sostenida.
-
El
general_logse desactiva automáticamente al terminar la captura; no queda activo de forma permanente. - Recuerda el alcance global: el informe mezcla la actividad de todas las bases de datos del servidor. Usa los valores reales del listado completo para atribuir consultas a una aplicación concreta.
9. Preguntas frecuentes
P: ¿Esta herramienta deja el general_log activado en el servidor?
No. La captura activa el general_log solo durante el periodo indicado y lo desactiva al terminar, de forma automática. Si la operación falla a mitad, el general_log puede quedar activo; en ese caso, vuelve a lanzar una captura corta (que lo desactivará al finalizar) o desactívalo manualmente con SET GLOBAL general_log=0.
P: ¿Afecta al rendimiento del servidor mientras se ejecuta?
Sí, ligeramente: registrar todas las consultas en disco añade sobrecada de E/S durante la ventana de captura. Por eso se recomienda un periodo corto. El impacto es temporal y desaparece al desactivarse el log.
P: ¿Puedo saber qué base de datos o aplicación genera cada consulta?
El Top muestra las consultas normalizadas (sin valores). Para atribuirlas, baja al listado completo, donde aparecen las sentencias con sus valores reales (nombres de tabla con sus prefijos, columnas, etc.), lo que normalmente permite identificar la aplicación de origen.
P: ¿Por qué dos consultas distintas aparecen como una sola en el Top?
Porque el Top agrupa por la forma de la consulta, sustituyendo los literales por num, 'xxx' o "xxx". Es intencionado: así se ve cuántas veces se ejecuta un mismo patrón, que es lo relevante para optimizar.
P: ¿Qué significa exactamente la columna “Ellapsed” del listado completo?
Es un valor relativo entre entradas consecutivas de la captura y sirve como indicador de secuencia/orden, no como una medida precisa del tiempo de ejecución de cada consulta. Para medir tiempos reales de ejecución conviene usar el slow query log o un EXPLAIN ANALYZE. El valor principal de rendimiento que ofrece este informe es la métrica AVG SQL/seconds y la frecuencia (Count) del Top.
P: ¿Cuántas consultas muestra el Top?
Las 10 formas de consulta más repetidas durante la ventana. El listado completo, en cambio, incluye todas las sentencias capturadas.
P: ¿Puedo capturar más tiempo si el servidor tiene poca actividad?
Sí, en servidores con poca carga puedes ampliar el periodo sin riesgo apreciable de llenar el disco. La advertencia sobre el espacio en disco aplica sobre todo a servidores con mucha actividad.