Introducción
MySQL Manager de Core-Admin incluye un conjunto de herramientas de monitorización InnoDB que permiten al administrador explorar en tiempo real el estado interno del motor de almacenamiento InnoDB en todos los servidores MySQL/MariaDB gestionados. Estas herramientas se organizan en tres secciones principales accesibles desde el árbol de navegación:
- InnoDB transactions — Transacciones activas en tiempo real
- InnoDB deadlocks — Último deadlock detectado con análisis automático
- InnoDB metrics — Métricas internas del motor con clasificación por importancia
Cada sección proporciona tanto una vista de listado como herramientas de análisis automático que generan informes con hallazgos, explicaciones y recomendaciones concretas.
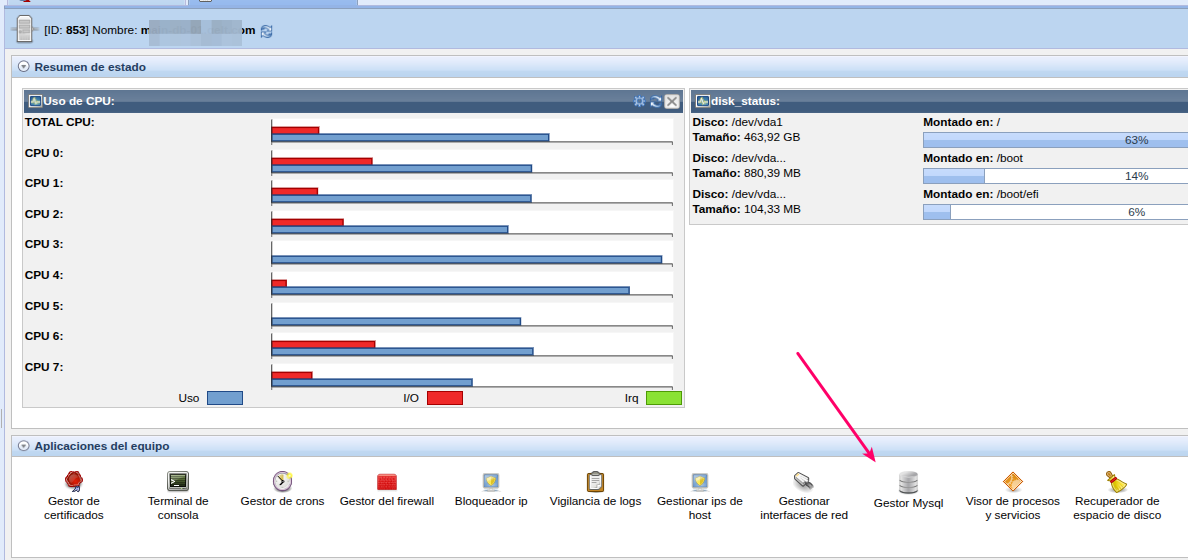
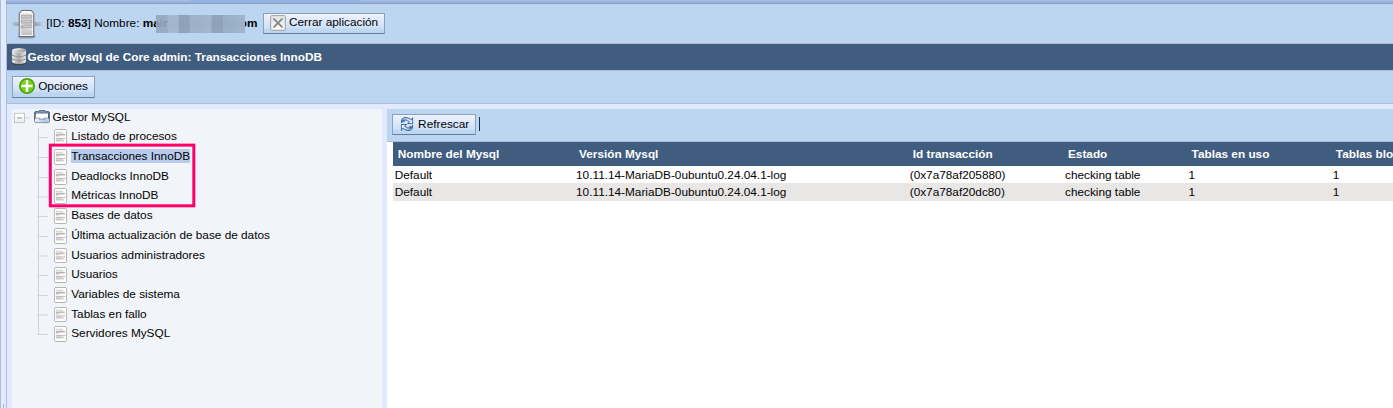
1. InnoDB Transactions — Transacciones activas
Qué muestra
Esta sección muestra todas las transacciones InnoDB activas en el momento de la consulta. Para cada transacción se muestra:
| Campo | Descripción |
|---|---|
| Id transaction | Identificador único de la transacción |
| Status | Estado actual (inserting, updating, fetching rows, etc.) |
| Ellapsed | Segundos que lleva activa la transacción |
| Tables in use | Número de tablas que está usando |
| Tables locked | Número de tablas que tiene bloqueadas |
| Host | Dirección IP del cliente que originó la transacción |
| User | Usuario MySQL que ejecuta la transacción |
| Query | Consulta SQL que se está ejecutando |
| Server | Nombre y versión del servidor MySQL/MariaDB |
Cómo interpretar los resultados
Las transacciones activas son una ventana al trabajo que está realizando el servidor en un momento dado. Los indicadores clave a observar son:
Transacciones de larga duración (Ellapsed alto)
Una transacción con un valor elevado de Ellapsed (por ejemplo, más de 30 segundos) puede ser problemática porque:
- Mantiene bloqueos de fila que impiden que otras transacciones avancen
- Impide al hilo de purga de InnoDB limpiar versiones antiguas de filas
- Puede provocar un crecimiento del
trx_rseg_history_len(visible en las métricas InnoDB)
Tables locked > 1
Si una transacción tiene varias tablas bloqueadas, su impacto potencial es mayor. Un bloqueo prolongado sobre múltiples tablas puede generar cadenas de esperas que afecten a muchas consultas.
Múltiples transacciones sobre la misma tabla
Cuando se observan varias transacciones activas operando sobre la misma tabla con operaciones de escritura (INSERT, UPDATE, DELETE), existe un riesgo de contención. Si además comparten rangos de filas, pueden producirse deadlocks.
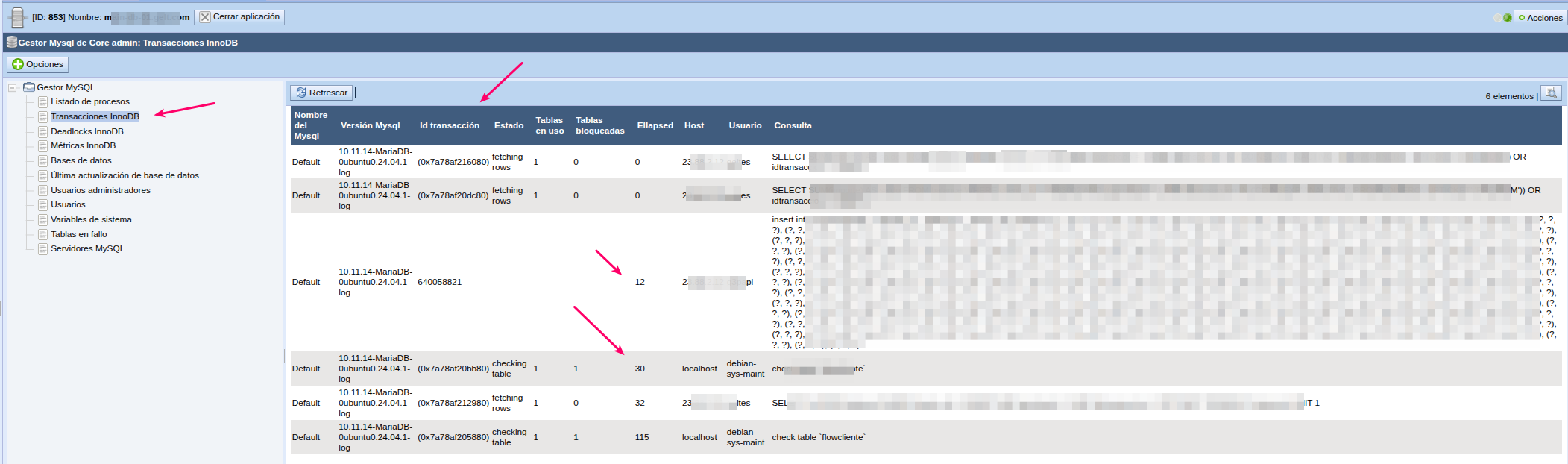
Uso práctico
- Pulse Refresh para obtener una instantánea actualizada de las transacciones activas
- Use la caja de búsqueda para filtrar por host, usuario o contenido de la query
- Haga clic en una transacción para ver su detalle completo, incluyendo la consulta SQL
2. InnoDB Deadlocks — Análisis de deadlocks
Qué muestra
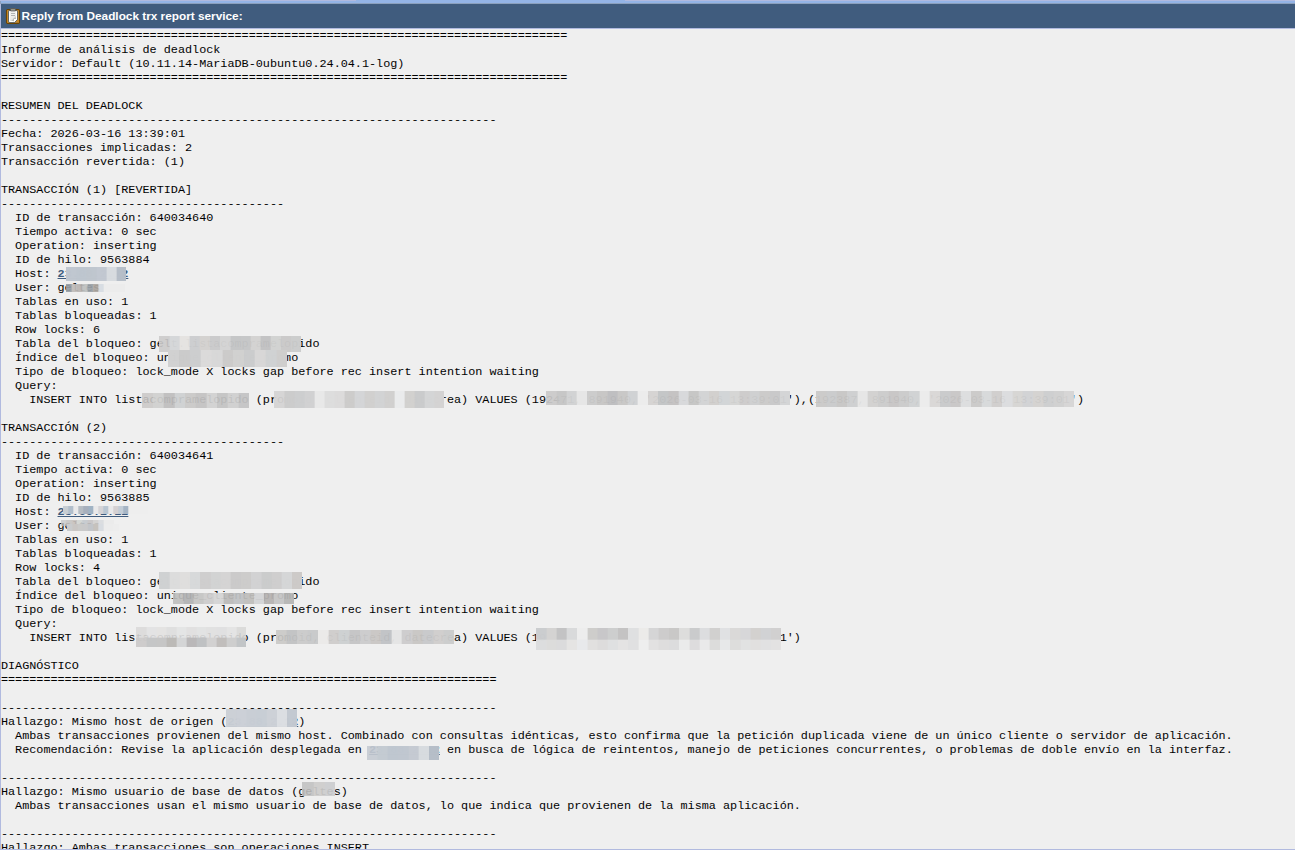
Esta sección muestra las transacciones implicadas en el último deadlock detectado por InnoDB. Cada registro corresponde a una de las transacciones del deadlock (normalmente 2). Para cada una se muestra:
| Campo | Descripción |
|---|---|
| Deadlock date | Fecha y hora en que ocurrió el deadlock |
| Transaction num | Número de transacción dentro del deadlock (1 o 2) |
| Transaction id | ID interno de la transacción |
| Active time | Tiempo que llevaba activa al producirse el deadlock |
| Operation | Operación que estaba realizando (inserting, updating…) |
| Tables in use / locked | Tablas en uso y bloqueadas |
| Row locks | Número de bloqueos de fila que mantenía |
| Host / User | Origen y usuario de la conexión |
| Query | Consulta SQL que causó el deadlock |
| Waiting lock table | Tabla sobre la que se esperaba el bloqueo |
| Waiting lock index | Índice involucrado en el bloqueo |
| Waiting lock info | Tipo de bloqueo esperado (gap lock, S lock, X lock…) |
| Rolled back | Si esta transacción fue la que InnoDB decidió revertir |
Cómo interpretar los resultados
Un deadlock ocurre cuando dos o más transacciones mantienen bloqueos que la otra necesita, creando una espera circular que no puede resolverse. InnoDB detecta esta situación automáticamente y revierte una de las transacciones para permitir que las demás continúen.
Campos clave para el diagnóstico manual:
-
Query: Compare las consultas de ambas transacciones. Si son idénticas, probablemente se trate de un doble envío desde la aplicación
-
Host: Si ambas vienen del mismo host, el problema está en un único cliente o servidor de aplicación
-
Waiting lock info: El tipo de bloqueo revela el mecanismo interno del deadlock:
-
lock_mode X locks gap before rec insert intention waiting— Un gap lock exclusivo con intención de inserción. Típico en INSERTs concurrentes sobre índices únicos -
lock mode S waiting— Bloqueo compartido en espera. Ocurre cuando InnoDB necesita verificar la existencia de un duplicado en un índice único
-
-
Rolled back: La transacción marcada como
yesfue la que InnoDB descartó. La otra completó con éxito -
Row locks: Una asimetría grande (ej. 14 vs 1) indica que una transacción había avanzado más antes del conflicto

Botón “Deadlock analysis report” — Informe de análisis automático
El botón “Deadlock analysis report” en la barra de herramientas genera un informe de diagnóstico completo que analiza automáticamente el último deadlock y produce un reporte estructurado con:
-
Resumen del deadlock: Fecha, número de transacciones implicadas y cuál fue revertida
-
Detalle de cada transacción: Toda la información relevante de cada transacción presentada de forma legible
-
Diagnóstico automático: El sistema detecta patrones y genera hallazgos con explicaciones técnicas:
- Consultas idénticas — Indica doble envío desde la aplicación
- Mismo host de origen — Confirma que el problema viene de un único cliente
- Mismo usuario — Las peticiones provienen de la misma aplicación
- Ambas operaciones INSERT — Patrón clásico de deadlock por INSERTs concurrentes con índice único
- Ambas operaciones UPDATE — Contención por orden de acceso a filas
- Índice único implicado — Explica el mecanismo de S lock / X lock en verificaciones de duplicados
- Gap lock detectado — Explica qué son los gap locks y sugiere evaluar el nivel de aislamiento READ COMMITTED
- Transacciones simultáneas (0 sec) — Refuerza la hipótesis de doble envío
- Bloqueos asimétricos — Una transacción había progresado más que la otra
-
Conclusión: Diagnóstico global basado en los patrones detectados, con una explicación clara de la causa raíz
Este informe está diseñado para que un administrador pueda comprender rápidamente qué ha provocado el deadlock y por dónde empezar a resolverlo, sin necesidad de interpretar manualmente la salida cruda de SHOW ENGINE INNODB STATUS.
3. InnoDB Metrics — Métricas internas del motor
Qué muestra
Esta sección presenta todas las métricas internas de InnoDB obtenidas de information_schema.INNODB_METRICS. Cada métrica incluye:
| Campo | Descripción |
|---|---|
| Name | Nombre técnico de la métrica |
| Importance | Nivel de importancia: max, high, medium, low |
| Subsystem | Subsistema de InnoDB al que pertenece |
| Count | Valor actual acumulado |
| Avg count | Promedio por segundo desde el inicio del servidor |
| Max count | Valor máximo observado |
| Min count | Valor mínimo observado |
| Comment | Descripción breve de la métrica |
Las métricas se presentan ordenadas por importancia (max primero, low último) y luego alfabéticamente dentro de cada nivel.
Clasificación por importancia
El sistema clasifica cada métrica según su relevancia para la detección de problemas de rendimiento:
Importancia MAX — Indicadores directos de crisis
Estas métricas señalan problemas activos que requieren atención inmediata:
| Métrica | Significado |
|---|---|
lock_deadlocks |
Número total de deadlocks detectados |
lock_row_lock_current_waits |
Transacciones esperando por bloqueos de fila ahora mismo |
lock_row_lock_time_max |
Tiempo máximo (ms) que una transacción esperó por un bloqueo |
buffer_pool_wait_free |
Veces que InnoDB esperó por una página libre en el buffer pool |
log_waits |
Esperas por espacio insuficiente en el redo log buffer |
lock_timeouts |
Transacciones que agotaron el tiempo de espera por bloqueos |
Un valor superior a 0 en cualquiera de estas métricas (excepto lock_row_lock_time_max, donde el umbral es 5000ms) indica un problema que ya ha ocurrido o está ocurriendo.
Importancia HIGH — Indicadores de presión y degradación
Señalan condiciones que degradan el rendimiento aunque no sean una crisis inmediata:
| Métrica | Significado |
|---|---|
lock_row_lock_waits |
Total de esperas por bloqueos de fila |
lock_row_lock_time / lock_row_lock_time_avg
|
Tiempo total/promedio en esperas de bloqueo |
trx_rseg_history_len |
Longitud de la lista de historial (indicador de purge lag) |
buffer_pool_reads |
Lecturas que requirieron acceso a disco |
buffer_pool_pages_free |
Páginas libres en el buffer pool |
buffer_pool_pages_dirty |
Páginas modificadas pendientes de escritura |
os_pending_reads / os_pending_writes
|
Operaciones de I/O pendientes |
purge_dml_delay_usec |
Retardo artificial en DML por purge lag |
trx_rollbacks |
Transacciones revertidas |
buffer_flush_sync_waits |
Esperas de flush síncrono (redo log lleno) |
Importancia MEDIUM — Contexto diagnóstico
Proporcionan contexto útil para el análisis pero no indican problemas por sí solas:
Incluyen métricas como buffer_pool_read_requests, buffer_pool_write_requests, buffer_pool_pages_total, os_data_reads, os_data_writes, log_writes, trx_rw_commits, file_num_open_files, entre otras.
Importancia LOW
Métricas detalladas para investigaciones específicas. Todas las métricas no clasificadas en los niveles anteriores se asignan a este nivel.
Cómo interpretar las métricas clave
Buffer Pool
El buffer pool es la zona de memoria donde InnoDB mantiene las páginas de datos e índices. Su correcto dimensionado es crítico:
-
buffer_pool_pages_freemuy bajo (< 5% del total) indica que el buffer pool necesita más memoria -
buffer_pool_wait_free> 0 indica que InnoDB tuvo que esperar por páginas libres — situación crítica -
Tasa de acierto = 1 - (
buffer_pool_reads/buffer_pool_read_requests). Si es inferior al 99%, el buffer pool es insuficiente -
buffer_pool_pages_dirtyalto respecto abuffer_pool_pages_dataindica que el flush no sigue el ritmo de escrituras
Bloqueos y contención
-
lock_deadlocks> 0 indica que han ocurrido deadlocks. Consulte la sección de Deadlocks para el detalle -
lock_row_lock_current_waits> 0 indica contención activa en este momento -
lock_row_lock_time_maxalto (> 5 segundos) indica que alguna transacción sufrió esperas graves -
lock_timeouts> 0 indica transacciones que fueron abortadas por tiempo de espera
Purge y undo log
-
trx_rseg_history_lenalto (> 10.000) indica que el hilo de purga no puede limpiar versiones antiguas de filas. Causa: transacciones de lectura de larga duración -
purge_dml_delay_usec> 0 indica que InnoDB está retrasando deliberadamente las operaciones DML porque la purga no da abasto
Redo log y I/O
-
log_waits> 0 indica que el redo log buffer es insuficiente -
buffer_flush_sync_waits> 0 indica que el redo log se llenó y forzó un flush síncrono -
os_pending_reads/os_pending_writes> 0 indica que el almacenamiento no puede seguir el ritmo
Botón “Metrics review report” — Informe de revisión de métricas
El botón “Metrics review report” genera un informe automático que evalúa las métricas contra umbrales conocidos y produce un reporte con hallazgos clasificados por severidad:
- CRÍTICO: Problemas que requieren atención inmediata (deadlocks, esperas activas, buffer pool agotado, timeouts)
- ADVERTENCIA: Condiciones de degradación (contención frecuente, purge lag, buffer pool bajo, I/O pendiente, rollbacks elevados)
- INFO: Condiciones notables pero no urgentes (esperas de bloqueos de registro, bloqueos a nivel de tabla)
Para cada hallazgo, el informe incluye:
- Valor: El dato concreto que disparó la alerta
- Descripción: Explicación técnica de lo que significa
- Recomendación: Acción concreta sugerida para resolver o mitigar el problema
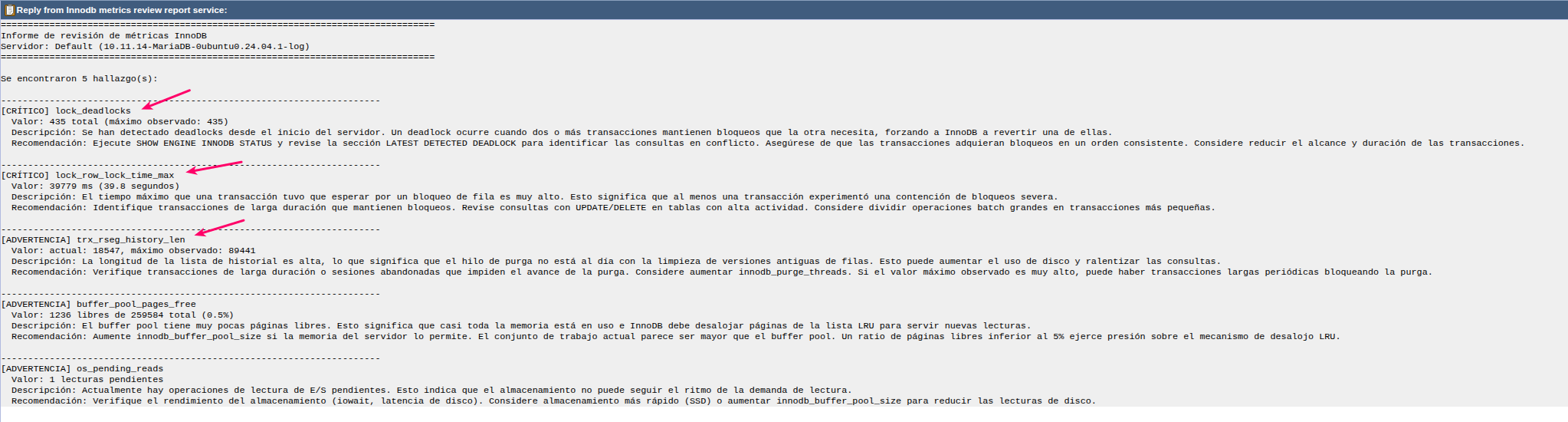
Si no se detectan problemas, el informe lo indicará explícitamente, confirmando que las métricas críticas y de alta importancia están dentro de parámetros normales.
Flujo de trabajo recomendado para diagnóstico
Revisión periódica (proactiva)
- Acceda a InnoDB metrics y pulse "Metrics review report"
- Si el informe muestra hallazgos, revise cada uno y aplique las recomendaciones
- Consulte InnoDB transactions para verificar si hay transacciones de larga duración activas
- Si existen deadlocks reportados, acceda a InnoDB deadlocks y pulse "Deadlock analysis report"
Ante un problema de rendimiento reportado
- Acceda a InnoDB transactions y pulse Refresh para ver el estado actual
- Busque transacciones con Ellapsed alto
- Identifique si hay muchas transacciones bloqueadas sobre la misma tabla
- Acceda a InnoDB metrics y revise las métricas de importancia max:
-
lock_row_lock_current_waits> 0 → Hay contención activa -
lock_deadlocksincrementando → Se están produciendo deadlocks -
buffer_pool_wait_free> 0 → El buffer pool está saturado
-
- Pulse “Metrics review report” para obtener un diagnóstico completo con recomendaciones
Ante un deadlock reportado por la aplicación
- Acceda a InnoDB deadlocks para ver las transacciones implicadas
- Pulse “Deadlock analysis report” para obtener el diagnóstico automático
- El informe le indicará:
- Si es un problema de doble envío desde la aplicación
- Si es un problema de contención por INSERTs/UPDATEs concurrentes
- Si el nivel de aislamiento de transacciones es un factor
- La acción concreta recomendada
- Comparta el informe con el equipo de desarrollo para que apliquen las correcciones en la aplicación
Referencia rápida de umbrales
| Métrica | Umbral de alerta | Severidad |
|---|---|---|
lock_deadlocks |
> 0 | CRÍTICO |
lock_row_lock_current_waits |
> 0 | CRÍTICO |
lock_row_lock_time_max |
> 5.000 ms | CRÍTICO |
buffer_pool_wait_free |
> 0 | CRÍTICO |
log_waits |
> 0 | CRÍTICO |
lock_timeouts |
> 0 | CRÍTICO |
lock_row_lock_waits (avg) |
> 0.1/sec | ADVERTENCIA |
lock_row_lock_time_avg |
> 100 ms | ADVERTENCIA |
trx_rseg_history_len |
> 10.000 | ADVERTENCIA |
trx_rseg_history_len (max) |
> 50.000 | ADVERTENCIA |
buffer_pool_pages_free |
< 5% del total | ADVERTENCIA |
| Buffer pool hit rate | < 99% | ADVERTENCIA |
buffer_pool_pages_dirty |
> 75% de data | ADVERTENCIA |
os_pending_reads / writes
|
> 0 | ADVERTENCIA |
purge_dml_delay_usec |
> 0 | ADVERTENCIA |
trx_rollbacks (avg) |
> 0.5/sec | ADVERTENCIA |
buffer_flush_sync_waits |
> 0 | ADVERTENCIA |
Glosario
| Término | Definición |
|---|---|
| Buffer pool | Zona de memoria donde InnoDB almacena páginas de datos e índices. Un buffer pool bien dimensionado reduce drásticamente los accesos a disco |
| Deadlock | Situación en la que dos o más transacciones se bloquean mutuamente, cada una esperando un recurso que la otra mantiene. InnoDB lo detecta automáticamente y revierte una transacción |
| Gap lock | Bloqueo sobre el espacio entre registros de un índice. Usado en nivel de aislamiento REPEATABLE READ para prevenir lecturas fantasma |
| Insert intention lock | Tipo especial de gap lock que indica la intención de insertar en un gap. Múltiples transacciones pueden tener insert intention locks en el mismo gap si no insertan en la misma posición |
| Purge | Proceso en segundo plano que limpia versiones antiguas de filas que ya no son necesarias para ninguna transacción activa |
| Redo log | Registro de escritura anticipada (WAL) que InnoDB usa para garantizar la durabilidad de las transacciones. Si se llena, fuerza un flush síncrono que bloquea las escrituras |
| Row lock | Bloqueo a nivel de fila individual. InnoDB usa bloqueos de fila (no de tabla) para permitir alta concurrencia |
| trx_rseg_history_len | Longitud de la lista de historial del undo log. Un valor alto indica que la purga está retrasada, generalmente por transacciones de lectura de larga duración |