1. Introducción
A continuación explicamos cómo funciona una parte del sistema antibot de Core-Admin, basada en la notificación del UserAgent que envía en propio bot.
Este sistema está basado en las experiencia en el terreno, alimentada por las incidencias o quejas recibidas por parte de los usuarios. Es decir, el listado es bastante seguro.
Sin embargo, habrá casos donde sea necesario configurar el mismo para evitar bloqueos, es decir, tráfico de bots que sí que es deseado.
2. Activación y aplicación
El sistema de antibots de core-admin se activa solo y se configura para todas las webs que se hayan dado de alta con el #WebhostingManagement.
Esta activación se realiza de manera automatizada a través del sistema #CradAlwaysUpdated de #CoreAdmin (normalmente por la noche entre las 05:00 y las 06:30 de la mañana).
Si no se desea esperar o se quiere repasar o reparar algo, se puede ejecutar manualmente el comando de activación (que también mostrará depuración de lo que hace):
>> crad-webhosting-mgr.pyc --apply-antibot-config --verbose
Esto creará los ficheros base y localizará los alojamientos a los que les falte esta configuración.
3. Exclusión de bots
El sistema, una vez desplegado, usará el siguiente fichero para saber qué bots no hay que bloquear. Es decir, bots permitidos:
>> cat /etc/core-admin/databases/crad-webhosting-mgr.antibots.filter
# Filter bots to avoid blocking them while using crad-webhosting-mgr.pyc --apply-antibot-config
# Declare one bot by line to avoid it to be excluded. Lines starting with # are considered comments.
# Once added to this file, rebuilding using:
# crad-webhosting-mgr.pyc --apply-antibot-config --verbose
Por defecto, el fichero está vacío (incluyendo el comentario que se muestra para una mejor guía).
Si se desean meter bots a excluir, hay que introducir la identificación del user-agent a excluir. Uno por línea.
¿Cómo saber qué cadenas de bots se pueden incluir? Hay varios métodos:
-
Se puede ejecutar el siguiente comando para saber el listado y lo que se puede excluir:
>> crad-webhosting-mgr.pyc --show-bots-for-antibots
AhrefsBot
Brightbot
Brightbot
serpstatbot
MJ12bot
BitSightBot
msnbot
… -
Normalmente el bot afectado y que necesitamos aceptar se verá con un 404 not found en el fichero de log del alojamiento:
# pista para localizar bots bloqueados
>> grep -i ’ 404 ’ /var/webs/dominio.com/logs/access -
También podemos revisar el fichero generado de bloqueo para saber los bots actualmente bloqueados, y las cadenas que podemos usar para excluir (marcadas en negrita):
>> head /etc/apache2/conf.d/core-admin-blocked-bots.conf
# Core-Admin Antibot configuration
# Use /etc/core-admin/databases/crad-webhosting-mgr.antibots.filter to include, one bot a line, to exclude from his configuration
RewriteEngine onRewriteCond %{HTTP_USER_AGENT} (AhrefsBot) [OR]
RewriteCond %{HTTP_USER_AGENT} (ahrefsbot) [OR]
RewriteCond %{HTTP_USER_AGENT} (Brightbot) [OR]
… -
Una vez identificado el bot a excluir, simplemente añadirlo, uno por línea, en el fichero de filtro indicado en la ayuda y en la cabecera de estos ficheros:
>> joe /etc/core-admin/databases/crad-webhosting-mgr.antibots.filter
-
También la ayuda de la herramienta incluye una referencia a este fichero de filtro de bots a excluir:
>> crad-webhosting-mgr.pyc --help
…
–apply-antibot-config
Adds antibot configuration for all hostings found
active. In case configuration is already added, it
updates configuration. You can also use /etc/core-
admin/databases/crad-webhosting-mgr.antibots.filter to
include one bot a line to be excluded from blocking.
After adding a bot in that exclude list, you must re-
rerun this tool.
4. Funcionamiento del bloqueo
Muchos bots genera accesos repetitivos y a urls que generan proceso (consumo php+cpu) que dificulta a la web su tarea de otorgar recursos para las visitas regulares y que le generan valor (para la venta, promoción, etc).
Al mismo tiempo, muchos bots realizan rastreo sin pedir permiso utilizando la información para integrarla en sus bases de datos para realizar procesos de IA, y similares, sin otorgar autoría.
En cualquiera de los casos, salvo que no se necesite algún bot en particular, la configuración por defecto que proporciona Core-Admin es segura y está en constante revisión para reducir al máximo el ruido y las incidencias.
Para saber cómo funciona el bloqueo, revisar el fichero de configuración que se genera, revisando:
>> head /etc/apache2/conf.d/core-admin-blocked-bots.conf
# Core-Admin Antibot configuration
# Use /etc/core-admin/databases/crad-webhosting-mgr.antibots.filter to include, one bot a line, to exclude from his configuration
RewriteEngine onRewriteCond %{HTTP_USER_AGENT} (AhrefsBot) [OR]
RewriteCond %{HTTP_USER_AGENT} (ahrefsbot) [OR]
RewriteCond %{HTTP_USER_AGENT} (Brightbot) [OR]
RewriteCond %{HTTP_USER_AGENT} (brightbot) [OR]
RewriteCond %{HTTP_USER_AGENT} (Brightbot) [OR]
RewriteCond %{HTTP_USER_AGENT} (brightbot) [OR]
…
RewriteCond %{HTTP_USER_AGENT} (rainbot) [OR]
RewriteCond %{HTTP_USER_AGENT} (ImagesiftBot) [OR]
RewriteCond %{HTTP_USER_AGENT} (imagesiftbot)
# All matching, denied…
RewriteRule ^ - [L,R=404]
Resumen: la configuración desplegada busca generar un 404 NOT FOUND para que el bot no solo no produzca carga en el servidor, sino también darle la señal de que en ese recurso no hay nada.
5. Adaptador dinámico de tráfico autorizado de bots
Por motivos de sobrecarga, que en ocasiones se pueden juntar con programaciones web pesadas, puede ser necesario adaptar temporalmente el tráfico aceptado para bots autorizados como Googlebot.
Es decir, hablamos de bots autorizados pero que necesitamos rechazar temporalmente para evitar problemas de carga y exceso de límites.
-
Para realizar manualmente un bloqueo de cierto bot, identificar una parte única del UserAgent. A continuación mostramos como ejemplo cómo bloquear durante 3 horas el bot de google:
>> crad-webhosting-mgr.pyc --create-temporal-blocking-by-user-agent=all 10800 Googlebot ‘Comentario’
En este caso bloqueamos bots identificados con “Googlebot”. Cambiar esta parte y periodo (10800 segundos) según necesidad.
-
Si necesitamos limitar este bloqueo solo para cierto dominio, cambiar “all” por el dominio en cuestión:
>> crad-webhosting-mgr.pyc --create-temporal-blocking-by-user-agent=dominio.com 10800 Googlebot ‘Comentario’
-
Para listar bloqueos temporales actualmente instalados, ejecutar:
>> crad-webhosting-mgr.pyc --list-temporal-blocking-by-user-agent
Id Is_active Name Blocking_period Agent_string Stamp Comments
1 |[*] |all |10800 |Googlebot |Tue Jun 24 10:06:11 2025 |core-
admin.loadavg_checker.run_evasive_actions: found system underload avg-last-minute=6.01, avg-max-reference=4.3 -
El bloqueo se borrará automáticamente, recargando las configuraciones necesarias, una vez se supere el periodo definido. Si se necesita borrar la regla antes, listar las reglas para obtener el id, y a continuación:
>> crad-webhosting-mgr.pyc --remove-temporal-blocking-by-user-agent=<rule-id>
Este sistema proporciona numerosas ventajas a los administradores del sitio y a los gestores de SEO:
-
Favorece destinar de manera preferente los recursos de la máquina a tráfico orgánico.
-
Permite aceptar tráfico googleBot mientras la máquina no entre en alta carga.
-
Dispensa el tener que estar administrando la consola de Google Web Search para ajustar, reducir o limitar el tráfico bot de google, generando una configuración dinámica que balancea estos dos aspectos (visitas orgánicas vs visitas de bots autorizados).
-
Permite mejorar los tiempos de respuesta de la máquina, en caso de encontrarse en alta carga, reduciendo o eliminando los tiempos de recuperación cuando estas cargas sean producidas por los bots de Google.
-
Al usarse códigos de respuesta 503 Server Unavailable, conseguimos comunicar a Google que los accesos y la frecuencia actual están causando problemas y también, permitimos que no afecte a la indexación, como podría ser el caso del código 404, 301 y 302.
6. Automatización adaptador dinámico de tráfico autorizado de bots GoogleBot + LoadAvgChecer
Existe una integración automatizada para máquinas con #WebhostingManagement por la cual se activan bloqueos automatizados de GoogleBot en el caso de que se encuentre la máquina con exceso de carga.
-
Este bloqueo automatizado aparecerá reflejado en los logs con el siguiente formato aproximado:
Jun 24 09:21:28 server core-admin-agent[5703]: core-admin.loadavg_checker.run_evasive_actions: found system underload avg-last-minute=7.9, avg-max-reference=4.3: after running command [crad-webhosting-mgr.pyc --create-temporal-blocking-by-user-agent=all 10800 Googlebot ‘core-admin.loadavg_checker.run_evasive_actions: found system underload avg-last-minute=7.9, avg-max-reference=4.3’], status=0: INFO: Operation completed: rebuild_temporal_blocking_user_agent: all rules reloaded (/etc/apache2/conf.d/core-admin-temporal-blocking-user-agent-001.conf) OK
-
Todos los bloqueos automatizados, tanto de esta integración como de otros orígenes quedan registrados y disponibles con:
# crad-webhosting-mgr.pyc --list-temporal-blocking-by-user-agent
Id Is_active Name Blocking_period Agent_string Stamp Comments
18 |[*] |all |10800 |Googlebot |Tue Jun 24 09:24:08 2025 |core-admin.loadavg_checker.run_evasive_actions: found system underload avg-last-minute=6.36, avg-max-reference=4.3
-
Ventajas de esta integración+automatización proporcionada por loadavg_checker de Core-Admin:
-
Reduce y en muchos casos elimina los eventos loadavg_checker debido a bots de google.
-
Reduce las incidencias de carga en general.
-
Reduce y en muchos casos elimina la tarea de evaluar si la carga es de debido a bots de google.
-
Elimina la tarea de estar pendiente para quitar reglas temporales
-
Mejora el funcionamiento de los servidores webs, limitando los bots de google, a sólo ser permitidos si no hay carga.
-
Aporta mayor independencia ante la programación de webs que reaccionan mal a las visitas de google bot: si se genera carga, se autorizará el bloqueo temporal.
-
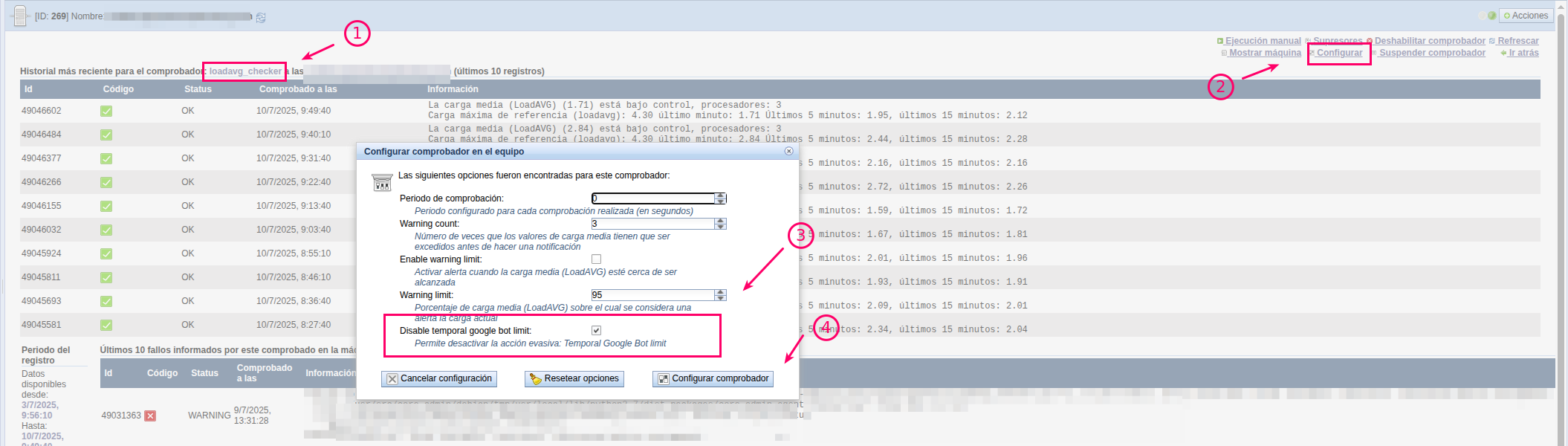
7. Cómo desactivar el adaptador dinámico
En caso de ser necesario desactivar esta opción, como administrador de la máquina, localice la siguiente opción asociada al loadavg_checker que es el comprobador que detecta el exceso de carga y lanza la acción evasiva de mitigar el tráfico de bots de google para desactivar ese comportamiento: